df <- tibble::tibble(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)
df$a <- (df$a - min(df$a, na.rm = TRUE)) /
(max(df$a, na.rm = TRUE) - min(df$a, na.rm = TRUE))
df$b <- (df$b - min(df$b, na.rm = TRUE)) /
(max(df$b, na.rm = TRUE) - min(df$a, na.rm = TRUE))
df$c <- (df$c - min(df$c, na.rm = TRUE)) /
(max(df$c, na.rm = TRUE) - min(df$c, na.rm = TRUE))
df$d <- (df$d - min(df$d, na.rm = TRUE)) /
(max(df$d, na.rm = TRUE) - min(df$d, na.rm = TRUE))7 Writing Functions
Reading: 18 minute(s) at 200 WPM
Videos: 20 minute(s)
Objectives
- Write your own functions in R
- Make good decisions about function arguments and returns
- Include side effects and / or error messages in your functions
- Extend your use of good R coding style
A function is a set of actions that we group together and name. Throughout this course, you’ve used a bunch of different functions in R that are built into the language or added through packages: mean, ggplot, filter. In this chapter, we’ll be writing our own functions.
7.1 When to write a function?
If you’ve written the same code (with a few minor changes, like variable names) more than twice, you should probably write a function instead of copy pasting. The motivation behind this is the “don’t repeat yourself” (DRY) principle (Wickham and Grolemund 2016). There are a few benefits to this rule:
Your code stays neater (and shorter), so it is easier to read, understand, and maintain.
If you need to fix the code because of errors, you only have to do it in one place.
You can re-use code in other files by keeping functions you need regularly in a file (or if you’re really awesome, in your own package!)
If you name your functions well, your code becomes easier to understand thanks to grouping a set of actions under a descriptive function name.
Learn more in R4DS
There is some extensive material on this subject in R for Data Science on functions. If you want to really understand how functions work in R, that is a good place to go.
If you are interested in reading about “best practices”, I recommend reading Best Practices for Scientific Computing (Wilson et al. 2014).
This example is modified from R for Data Science (Wickham and Grolemund 2016, chap. 19).
What does this code do? Does it work as intended?
The code rescales a set of variables to have a range from 0 to 1. But, because of the copy-pasting, the code’s author made a mistake and forgot to change an a to b.
Writing a function to rescale a variable would prevent this type of copy-paste error.
To write a function, we first analyze the code to determine how many inputs it has
This code has only one input: df$a.
To convert the code into a function, we first rewrite it using general names
In this case, it might help to replace df$a with x.
[1] 0.12643112 0.42901602 0.97391841 0.77221475 0.07277565 0.73790707
[7] 0.62944150 0.00000000 1.00000000 0.27256404Then, we make it a bit easier to read, removing duplicate computations if possible (for instance, computing min two times).
In R, we can use the range function, which computes the maximum and minimum at the same time and returns the result as c(min, max)
rng <- range(x, na.rm = T)
(x - rng[1])/(rng[2] - rng[1]) [1] 0.12643112 0.42901602 0.97391841 0.77221475 0.07277565 0.73790707
[7] 0.62944150 0.00000000 1.00000000 0.27256404Finally, we turn this code into a function
rescale01 <- function(x) {
rng <- range(x, na.rm = T)
(x - rng[1])/(rng[2] - rng[1])
}
rescale01(df$a) [1] 0.12643112 0.42901602 0.97391841 0.77221475 0.07277565 0.73790707
[7] 0.62944150 0.00000000 1.00000000 0.27256404- The name of the function,
rescale01, describes what the function does - it rescales the data to between 0 and 1. - The function takes one argument, named
x; any references to this value within the function will usexas the name. This allows us to use the function ondf$a,df$b,df$c, and so on, withxas a placeholder name for the data we’re working on at the moment. - The code that actually does what your function is supposed to do goes in the body of the function, between
{and} - The function returns the last value computed: in this case,
(x - rng[1])/(rng[2]-rng[1]). You can make this explicit by adding areturn()statement around that calculation.
The process for creating a function is important: first, you figure out how to do the thing you want to do. Then, you simplify the code as much as possible. Only at the end of that process do you create an actual function.
7.2 Syntax

In R, functions are defined (or assigned names) the same as other variables, using <-, but we specify the arguments a function takes by using the function() statement. The contents of the function are contained within { and }. If the function returns a value, a return() statement can be used; alternately, if there is no return statement, the last computation in the function will be returned.
7.3 Arguments and Parameters
An argument is the name for the object you pass into a function.
A parameter is the name for the object once it is inside the function (or the name of the thing as defined in the function).
Let’s examine the difference between arguments and parameters by writing a function that takes a puppy’s name and returns “
dog <- "Eddie"
goodpup <- function(name) {
paste(name, "is a good pup!")
}
goodpup(dog)[1] "Eddie is a good pup!"In this example R function, when we call goodpup(dog), dog is the argument. name is the parameter.
What is happening inside the computer’s memory as goodpup runs?
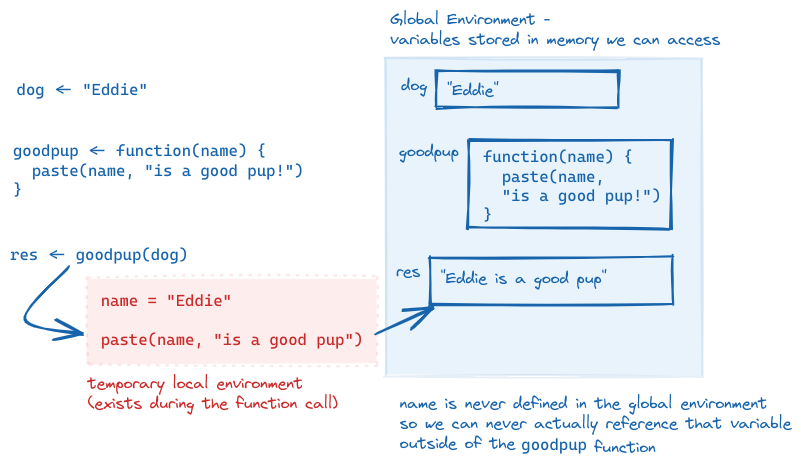
goodpup, showing that name is only defined within the local environment that is created while goodpup is running. We can never access name in our global environment.This is why the distinction between arguments and parameters matters. Parameters are only accessible while inside of the function - and in that local environment, we need to call the object by the parameter name, not the name we use outside the function (the argument name).
We can even call a function with an argument that isn’t defined outside of the function call: goodpup("Tesla") produces “Tesla is a good pup!”. Here, I do not have a variable storing the string “Tesla”, but I can make the function run anyways. So “Tesla” here is an argument to goodpup but it is not a variable in my environment.
This is a confusing set of concepts and it’s ok if you only just sort of get what I’m trying to explain here. Hopefully it will become more clear as you write more code.
Example
For each of the following blocks of code, identify the function name, function arguments, parameter names, and return statements. When the function is called, see if you can predict what the output will be.
7.3.1 Named Arguments and Parameter Order
In the examples above, you didn’t have to worry about what order parameters were passed into the function, because there were 0 and 1 parameters, respectively. But what happens when we have a function with multiple parameters?
divide <- function(x, y) {
x / y
}In this function, the order of the parameters matters! divide(3, 6) does not produce the same result as divide(6, 3). As you might imagine, this can quickly get confusing as the number of parameters in the function increases.
In this case, it can be simpler to use the parameter names when you pass in arguments.
divide(3, 6)[1] 0.5divide(x = 3, y = 6)[1] 0.5divide(y = 6, x = 3)[1] 0.5divide(6, 3)[1] 2divide(x = 6, y = 3)[1] 2divide(y = 3, x = 6)[1] 2As you can see, the order of the arguments doesn’t much matter, as long as you use named arguments, but if you don’t name your arguments, the order very much matters.
7.4 Input Validation
When you write a function, you often assume that your parameters will be of a certain type. But you can’t guarantee that the person using your function knows that they need a certain type of input. In these cases, it’s best to validate your function input.
In R, you can use stopifnot() to check for certain essential conditions. If you want to provide a more illuminating error message, you can check your conditions using if() or if(){ } else{ } and then use stop("better error message") in the body of the if or else statement.
add <- function(x, y) {
x + y
}
add("tmp", 3)Error in x + y: non-numeric argument to binary operatoradd <- function(x, y) {
stopifnot(is.numeric(x),
is.numeric(y)
)
x + y
}
add("tmp", 3)Error in add("tmp", 3): is.numeric(x) is not TRUEadd(3, 4)[1] 7add <- function(x, y) {
x + y
}
add <- function(x, y) {
if(is.numeric(x) & is.numeric(y)) {
x + y
} else {
stop("Argument input for x or y is not numeric")
}
}
add("tmp", 3)Error in add("tmp", 3): Argument input for x or y is not numericadd(3, 4)[1] 7add <- function(x, y) {
x + y
}
add <- function(x, y) {
if(!is.numeric(x) | !is.numeric(y)) {
stop("Argument input for x or y is not numeric")
}
x + y
}
add("tmp", 3)Error in add("tmp", 3): Argument input for x or y is not numericadd(3, 4)[1] 7Input validation is one aspect of defensive programming - programming in such a way that you try to ensure that your programs don’t error out due to unexpected bugs by anticipating ways your programs might be misunderstood or misused. If you’re interested, Wikipedia has more about defensive programming.
7.5 Scope
When talking about functions, for the first time we start to confront a critical concept in programming, which is scope. Scope is the part of the program where the name you’ve given a variable is valid - that is, where you can use a variable.
A variable is only available from inside the region it is created.
What do I mean by the part of a program? The lexical scope is the portion of the code (the set of lines of code) where the name is valid.
The concept of scope is best demonstrated through a series of examples, so in the rest of this section, I’ll show you some examples of how scope works and the concepts that help you figure out what “scope” actually means in practice.
7.5.1 Name Masking
Scope is most clearly demonstrated when we use the same variable name inside and outside a function. Note that this is 1) bad programming practice, and 2) fairly easily avoided if you can make your names even slightly more creative than a, b, and so on. But, for the purposes of demonstration, I hope you’ll forgive my lack of creativity in this area so that you can see how name masking works.
What does this function return, 10 or 20?
a <- 10
myfun <- function() {
a <- 20
a
}
myfun()
myfun(). Because a=20 inside myfun(), when we call myfun(), we get the value of a within that environment, instead of within the global environment.a <- 10
myfun <- function() {
a <- 20
a
}
myfun()[1] 20a[1] 10The lexical scope of the function is the area that is between the braces. Outside the function, a has the value of 10, but inside the function, a has the value of 20. So when we call myfun(), we get 20, because the scope of myfun is the local context where a is evaluated, and the value of a in that environment dominates.
This is an example of name masking, where names defined inside of a function mask names defined outside of a function.
7.5.2 Environments and Scope
Another principle of scoping is that if you call a function and then call the same function again, the function’s environment is re-created each time. Each function call is unrelated to the next function call when the function is defined using local variables.
myfun <- function() {
if aa is not defined
aa <- 1
else
aa <- aa + 1
}
myfun()
myfun()
What does this output?
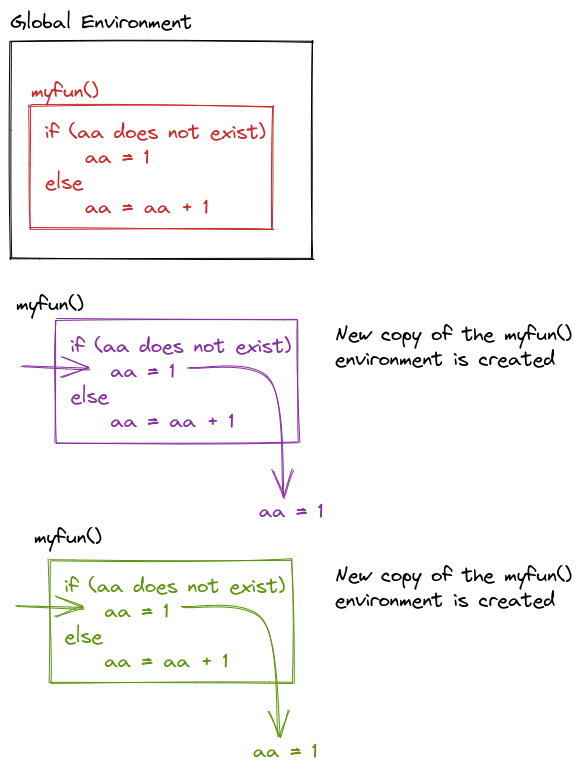
myfun() is called, that template is used to create a new environment. This prevents successive calls to myfun() from affecting each other – which means a = 1 every time.7.5.3 Dynamic Lookup
Scoping determines where to look for values – when, however, is determined by the sequence of steps in the code. When a function is called, the calling environment (the global environment or set of environments at the time the function is called) determines what values are used.
If an object doesn’t exist in the function’s environment, the global environment will be searched next; if there is no object in the global environment, the program will error out. This behavior, combined with changes in the calling environment over time, can mean that the output of a function can change based on objects outside of the function.
myfun <- function(){
x + 1
}
x <- 14
myfun()
x <- 20
myfun()
What will the output be of this code?
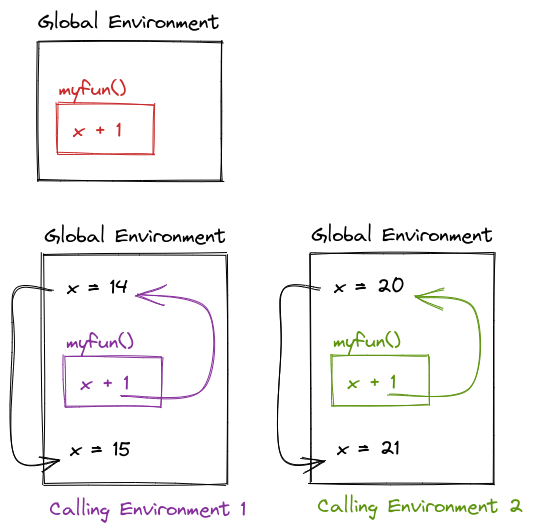
myfun <- function() {
x + 1
}
x <- 14
myfun()[1] 15x <- 20
myfun()[1] 21What does the following function return? Make a prediction, then run the code yourself. (Taken from (Wickham 2015, chap. 6))
f <- function(x) {
f <- function(x) {
f <- function() {
x ^ 2
}
f() + 1
}
f(x) * 2
}
f(10)f <- function(x) {
f <- function(x) {
f <- function() {
x ^ 2
}
f() + 1
}
f(x) * 2
}
f(10)[1] 2027.5.4 Tutorial - Writing Functions
VisitRStudio Primer - Writing Functions
I highly recommend you work through every tutorial except Loops!
7.6 Debugging
Now that you’re writing functions, it’s time to talk a bit about debugging techniques. This is a lifelong topic - as you become a more advanced programmer, you will need to develop more advanced debugging skills as well (because you’ll become more adept at screwing things up).
Let’s start with the basics: print debugging.
7.6.1 Print Debugging
This technique is basically exactly what it sounds like. You insert a ton of print statements to give you an idea of what is happening at each step of the function.
Let’s try it out on the previous example (see what I did there?)
Note that I’ve modified the code slightly so that we store the value into returnval and then return it later - this allows us to see the code execution without calling functions twice (which would make the print output a bit more confusing).
f <- function(x) {
print ("Entering Outer Function")
print (paste("x =", x))
f <- function(x) {
print ("Entering Middle Function")
print (paste("x = ", x))
f <- function() {
print ("Entering Inner Function")
print (paste("x = ", x))
print (paste("Inner Function: Returning", x^2))
x ^ 2
}
returnval <- f() + 1
print (paste("Middle Function: Returning", returnval))
returnval
}
returnval <- f(x) * 2
print (paste("Outer Function: Returning", returnval))
returnval
}
f(10)[1] "Entering Outer Function"
[1] "x = 10"
[1] "Entering Middle Function"
[1] "x = 10"
[1] "Entering Inner Function"
[1] "x = 10"
[1] "Inner Function: Returning 100"
[1] "Middle Function: Returning 101"
[1] "Outer Function: Returning 202"[1] 2027.6.2 General Debugging Strategies
Debugging: Being the detective in a crime movie where you are also the murderer. - some t-shirt I saw once
The overall process is well described in Advanced R by H. Wickham1; I’ve copied it here because it’s such a succinct distillation of the process, but I’ve adapted some of the explanations to this class rather than the original context of package development.
Realize that you have a bug
Google! In R you can automate this with the
erroristandsearcherpackages, but general Googling the error + the programming language + any packages you think are causing the issue is a good strategy.-
Make the error repeatable: This makes it easier to figure out what the error is, faster to iterate, and easier to ask for help.
- Use binary search (remove 1/2 of the code, see if the error occurs, if not go to the other 1/2 of the code. Repeat until you’ve isolated the error.)
- Generate the error faster - use a minimal test dataset, if possible, so that you can ask for help easily and run code faster. This is worth the investment if you’ve been debugging the same error for a while.
- Note which inputs don’t generate the bug – this negative “data” is helpful when asking for help.
Figure out where it is. Debuggers may help with this, but you can also use the scientific method to explore the code, or the tried-and-true method of using lots of
print()statements.Fix it and test it. The goal with tests is to ensure that the same error doesn’t pop back up in a future version of your code. Generate an example that will test for the error, and add it to your documentation.
There are several other general strategies for debugging:
Retype (from scratch) your code
This works well if it’s a short function or a couple of lines of code, but it’s less useful if you have a big script full of code to debug. However, it does sometimes fix really silly typos that are hard to spot, like having typed<--instead of<-in R and then wondering why your answers are negative.Visualize your data as it moves through the program. This may be done using
print()statements, or the debugger, or some other strategy depending on your application.Tracing statements. Again, this is part of
print()debugging, but these messages indicate progress - “got into function x”, “returning from function y”, and so on.Rubber ducking. Have you ever tried to explain a problem you’re having to someone else, only to have a moment of insight and “oh, never mind”? Rubber ducking outsources the problem to a nonjudgmental entity, such as a rubber duck2. You simply explain, in terms simple enough for your rubber duck to understand, exactly what your code does, line by line, until you’ve found the problem. A more thorough explanation can be found at gitduck.com.

Do not be surprised if, in the process of debugging, you encounter new bugs. This is a problem that’s well-known it has an xkcd comic. At some point, getting up and going for a walk may help. Redesigning your code to be more modular and more organized is also a good idea.
These next two sections are included as FYI, but you don’t have to read them just now. They’re important, but not urgent, if that makes sense.
Dividing Problems into Smaller Parts
“Divide each difficulty into as many parts as is feasible and necessary to resolve it.” -René Descartes, Discourse on Method
In programming, as in life, big, general problems are very hard to solve effectively. Instead, the goal is to break a problem down into smaller pieces that may actually be solveable.
We’ll start with a non-programming example:
General problem statement : “I’m exhausted all the time”
Ok, so this is a problem that many of us have from time to time (or all the time). If we get a little bit more specific at outlining the problem, though, we can sometimes get a bit more insight into how to solve it.Specific problem statement: “I wake up in the morning and I don’t have any energy to do anything. I want to go back to sleep, but I have too much to do to actually give in and sleep. I spend my days worrying about how I’m going to get all of the things on my to-do list done, and then I lie awake at night thinking about how many things there are to do tomorrow. I don’t have time for hobbies or exercise, so I drink a lot of coffee instead to make it through the day.”
This is a much more specific list of issues, and some of these issues are actually things we can approach separately.-
Separating things into solvable problems:
Moving through the list above, we can isolate a few issues. Some of these issues are undoubtedly related to each other, but we can approach them separately (for the most part).- Poor quality sleep (tired in the morning, lying awake at night)
- Too many things to do (to-do list)
- Chemical solutions to low energy (coffee during the day)
- Anxiety about completing tasks (worrying, insomnia)
- Lack of personal time for hobbies or exercise
-
Brainstorm Solutions:
- Get a check-up to rule out any other issues that could cause sleep quality degradation - depression, anxiety, sleep apnea, thyroid conditions, etc.
- Ask the doctor about taking melatonin supplements for a short time to ensure that sleep starts off well (note, don’t take medical advice from a stats textbook!)
- Reformat your to-do list:
- Set time limits for things on the to-do list
- Break the to-do list into smaller, manageable tasks that can be accomplished within a relatively short interval - such as an hour
- Sort the to-do list by priority and level of “fun” so that each day has a few hard tasks and a couple of easy/fun tasks. Do the hard tasks first, and use the easy/fun tasks as a reward.
- Set a time limit for caffeine (e.g. no coffee after noon) so that caffeine doesn’t contribute to poor quality sleep
- Address anxiety with medication (from 1), scheduled time for mindfulness meditation, and/or self-care activities
- Scheduling time for exercise/hobbies
- scheduling exercise in the morning to take advantage of the endorphins generated by working out
- scheduling hobbies in the evening to reward yourself for a day’s work and wind down work well before bedtime
- Get a check-up to rule out any other issues that could cause sleep quality degradation - depression, anxiety, sleep apnea, thyroid conditions, etc.
Approach each sub-problem separately
When the sub-problem has a viable solution, move on to the next sub-problem. Don’t try to tackle everything at once. Here, that might look like this list, where each step is taken separately and you give each thing a few days to see how it affects your sleep quality. In programming, of course, this list would perhaps be a bit more sequential, but real life is messy and the results take a while to populate.
- [1] Make the doctor’s appointment.
- [5] While waiting for the appointment, schedule exercise early in the day and hobbies later in the day to create a “no-work” period before bedtime.
- [1] Go to the doctor’s appointment, follow up with any concerns.
- [1] If doctor approves, start taking melatonin according to directions
- [2] Work on reformatting the to-do list into manageable chunks. Schedule time to complete chunks using your favorite planning method.
- [4] If anxiety is still an issue after following up with the doctor, add some mindfulness meditation or self-care to the schedule in the mornings or evenings.
- [3] If sleep quality is still an issue, set a time limit for caffeine
- [2] Revise your to-do list and try a different tactic if what you were trying didn’t work.
Here’s another example of how to break down a real-world personal problem in programming/debugging style.
Minimal Working (or Reproducible) Examples
If all else has failed, and you can’t figure out what is causing your error, it’s probably time to ask for help. If you have a friend or buddy that knows the language you’re working in, by all means ask for help sooner - use them as a rubber duck if you have to. But when you ask for help online, often you’re asking people who are much more knowledgeable about the topic - members of R core browse stackoverflow and may drop in and help you out. Under those circumstances, it’s better to make the task of helping you as easy as possible because it shows respect for their time. The same thing goes for your supervisors and professors.

So, with that said, there are numerous resources for writing what’s called a “minimal working example”, “reproducible example” (commonly abbreviated reprex), or MCVE (minimal complete verifiable example). Much of this is lifted directly from the StackOverflow post describing a minimal reproducible example.
The goal is to reproduce the error message with information that is
- minimal - as little code as possible to still reproduce the problem
- complete - everything necessary to reproduce the issue is contained in the description/question
- reproducible - test the code you provide to reproduce the problem.
You should format your question to make it as easy as possible to help you. Make it so that code can be copied from your post directly and pasted into an R script or notebook (e.g. Quarto document code chunk). Describe what you see and what you’d hope to see if the code were working.
Other resources:
- reprex package: Do’s and Don’ts
- How to use the reprex package - vignette with videos from Jenny Bryan
- reprex magic - Vignette adapted from a blog post by Nick Tierney
7.7 Styling Functions
Part of writing reproducible and shareable code is following good style guidelines. Mostly, this means choosing good object names and using white space in a consistent and clear way.
You should have already seen the sections of the Tidyverse Style Guide relevant to piping, plotting, and naming objects. This week we are extending these style guides to functions.
I would highly recommend reading through the style guide for naming functions, what to do with long lines, and the use of comments.
Read the tidyverse style guide for functions.
In summary, designing functions is somewhat subjective, but there are a few principles that apply:
- Choose a good, descriptive names
- Your function name should describe what it does, and usually involves a verb.
- Your argument names should be simple and / or descriptive.
- Names of variables in the body of the function should be descriptive.
- Output should be very predictable
- Your function should always return the same object type, no matter what input it gets.
- Your function should expect certain objects or object types as input, and give errors when it does not get them.
- Your function should give errors or warnings for common mistakes.
- Default values of arguments should only be used when there is a clear common choice.
- The body of the function should be easy to read.
- Code should use good style principles.
- There should be occasional comments to explain the purpose of the steps.
- Complicated steps, or steps that are repeated many times, should be written into separate functions (sometimes called helper functions).
- Functions should be self-contained.
- They should not rely on any information besides what is given as input.
- (Relying on other functions is fine, though)
- They should not alter the Global Environment
- Functions should never load or install packages!
References
Wickham, H. 2015. Advanced R. Chapman & Hall/CRC The R Series. CRC Press. https://books.google.com/books?id=FfsYCwAAQBAJ.
Wickham, H., and G. Grolemund. 2016. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. O’Reilly Media. https://books.google.com/books?id=vfi3DQAAQBAJ.
Wilson, Greg, Dhavide A Aruliah, C Titus Brown, Neil P Chue Hong, Matt Davis, Richard T Guy, Steven HD Haddock, et al. 2014. “Best Practices for Scientific Computing.” PLoS Biology 12 (1): e1001745.
the 0th step is from the 1st edition, the remaining steps are from the 2nd.↩︎
Some people use cats, but I find that they don’t meet the nonjudgmental criteria. Of course, they’re equally judgmental whether your code works or not, so maybe that works if you’re a cat person, which I am not. Dogs, in my experience, can work, but often will try to comfort you when they realize you’re upset, which both helps and lessens your motivation to fix the problem. A rubber duck is the perfect dispassionate listener.↩︎